
Snowflake Architecture and Key Concepts for Data Warehouse
Snowflake is a cloud-based data warehouse that provides the speed, scalability, and flexibility of a traditional data warehouse with the simplicity of an on-demand service. Snowflake makes it easy to build and manage your enterprise-grade data warehouse at a fraction of the cost of traditional solutions.
What is Snowflake?
Snowflake is a data warehouse as a service (DaaS). This means that you pay to use Snowflake, rather than buying the hardware and software yourself.
Snowflake is a cloud-based data warehouse. It runs on AWS (Amazon Web Services), but you don’t need to have an AWS account if you don’t want it; they’ll let you run their software on other cloud providers as well.
Snowflake is built for petabyte-scale workloads and very large datasets more than 100 TB of data in your warehouse at any given time. If your team doesn’t think this sounds big enough yet, keep reading!

What is Snowflake Architecture?
Snowflake is a cloud-based data warehouse as a service built for the enterprise. It’s designed to help you extract maximum value from all your data for improved business performance, faster time to insights, and lower costs.
Because Snowflake is built on the Google Cloud Platform (GCP) and integrates with GCP services like BigQuery, Cloud Natural Language API, Storage Transfer Service (STS), Pub/Sub API, etc., it provides you with powerful capabilities including.
- The multi-tenant architecture allows you to provision resources independently of other users in the same organization and across organizations.
- Flexibility in defining schemas through relational tables or star schemas.
- Support for richly structured JSON documents with nested structure (e.g., nested lists).
Types of Snowflake Data Warehouse Architecture
There are two types of data warehouses, the star schema, and the snowflake schema.
- The distinction between these two is based on how tables are related to each other. In a star schema, all tables relate directly to one another through a single fact table.
In contrast, in a snowflake data warehouse architecture, multiple dimensions can exist for the same fact table.
- The primary difference between these two types of architectures is that there will be fewer joins required in a star schema compared with that of snowflake architecture.
However, there may be more tables in total due to its robustness as it allows for more granularity and flexibility when reporting against compliance requirements (such as Sarbanes Oxley).
Snowflake – Data Warehouse as a Service
it’s a cloud database that you can use to build your data warehouse. It provides an on-demand, fully managed, and secure platform for managing large volumes of structured and semi-structured data across multiple environments.
Components of Data Warehouse Architecture
A data warehouse is a repository containing the historical and current data used by an organization. A traditional data warehousing architecture consists of a few key components:
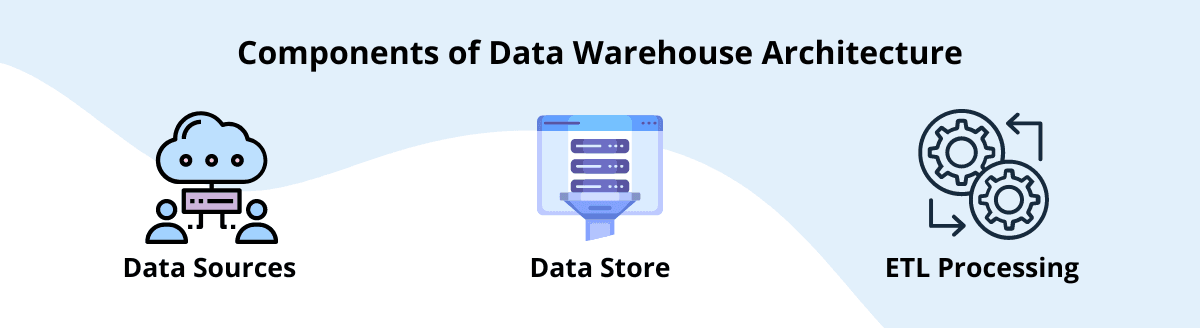
1. Data sources
The raw source of information for your users. Examples include transactional systems (such as ERP or POS), operational systems (such as CRM), social media, and web log files.
2. Datastore
The collection of tables in your database that makes up the fact table. Fact tables are joined by dimension tables to create dimensional models that contain meaningful business metrics.
3. ETL processing
A set of tools is used to extract, transform, and load raw data into an operational data store or staging area before sending it through a series of multi-step processes before loading it into the fact table.
Why Snowflake is important?
- Snowflake allows you to run SQL statements against massive amounts of transactional data very fast. And if you need more power than just SQL.
- Snowflake can run operations on your data using MapReduce or Spark two frameworks for processing large datasets (think terabytes or petabytes).
- The reason why Snowflake is so important is that it gives companies the ability to collect, store, and analyze petabytes of data quickly and easily.
- It also allows them to run SQL statements against huge amounts of transactional data very fast. If they need more power than just SQL.
- Snowflake will run operations on their data using MapReduce or Spark two frameworks for processing large datasets (think terabytes or petabytes).

Conclusion
The Snowflake architecture is a distributed data warehouse that uses the Snowflake Data Loader to load data. It is also known as an ETL tool, which stands for Extract Transform and Load. The ETL process loads data from multiple sources into the central repository, where it can be joined together to create a unified view of your business.
FAQs on Snowflake Architecture
If you’re new to Snowflake, here are some key concepts to keep in mind:
Snowflake is a data warehouse service that allows users to store and analyze massive amounts of data. It’s built on Apache Spark, which allows for lightning-fast analysis and processing of larger datasets than most other methods.
Snowflake separates the storage layer from the compute layer, so you can scale up storage as needed and scale down compute resources when they aren’t needed. You only pay for what you use, so there’s no need to provide extra space on your own servers if you don’t need it.
You can use a variety of tools with Snowflake, including SQL queries (with SnowSQL), Python scripts (with PySpark), and R scripts (with SparkR).
Snowflake architecture is a data warehouse architecture that uses a star schema. It’s named for the “snowflakes” that each table contains—that is, it has all of the information necessary for one fact or analysis stored at a single point in the database instead of being spread out over multiple tables.
Snowflake key concepts are determined by the nature and scope of your data warehouse. The size of your data warehouse will determine how many snowflakes you need to create.
Snowflake architecture involves storing related data together in a hierarchical structure. Data is stored in its original format, which means it can be retrieved quickly and efficiently. This makes it easier to access the data you need without having to extract it from your database first.
The key concepts of snowflake architecture include,
Data Warehouse – A repository where all your data is stored. You can use a relational database or cloud-based solution like Amazon Redshift or Google BigQuery. You should also consider using ETL tools to move data into your warehouse.
Dimension Tables – The dimensions are tables that hold descriptive information about each row in your fact table. For example, if you have sales by region, product category, customer segmentation, etc., these would be dimensions for each sales record.
Fact Table – The fact table contains numeric values related to each row in the dimension tables (i.e., sales by region). It also contains other metadata such as time series data and summaries of aggregates overtime periods.
The snowflake key is a unique identifier that can be used to join data from multiple tables. It consists of two parts: the table number and the primary key for that table.
Because we’re trying to join data from multiple tables, those tables may have different primary keys. To make sure we’re joining the right data, we need a way to uniquely identify each row in all of our tables. That’s where the snowflake key comes in!
The benefit of this design is that you can easily organize your data by date, customer, product type, and other dimensions without needing to build many separate tables.
This makes data retrieval faster than it would be if you used separate tables because you don’t have to join them together before retrieving data.
It also enables you to quickly answer questions about your business by combining multiple pieces of information into one query.
You could—but it would be pretty inefficient! If you have tables that are already joined together and only need one or two extra dimensions, then it might make sense to do so; otherwise, it’s probably best not to create new tables just for those extra dimensions.
A snowflake schema is a database design in which tables are normalized into a star schema by creating “fact tables” that connect to multiple “dimension” tables.
The snowflake schema provides for a more normalized data model than the original star schema. It allows for easier maintenance and more flexibility in adding new dimensions to the data warehouse.




